はじめに#
2025年4月9日、GoogleがAgent2Agent(A2A)プロトコルを発表 してから半年以上が経過し、多くの開発者がマルチエージェントシステムの構築に取り組んでいます。
A2Aは複雑なコンポーネント構成とエージェント間通信を持つため、処理フローをトレースとして可視化することがLLM Opsにおいて重要です。
本記事では、LangfuseとCloud Traceを使用してA2A × ADKエージェントの挙動を観測し、実用的な分析のための観測粒度の最適化方法を解説します。
実装環境#
使用したライブラリ#
本記事で使用したライブラリとそのバージョンは以下の通りです。
requirements.txt
google-adk[a2a]
google-genai
langfuse
python-dotenv
opentelemetry-instrumentation-google-genai
opentelemetry-exporter-gcp-logging
opentelemetry-exporter-gcp-monitoring
opentelemetry-exporter-otlp-proto-grpc
opentelemetry-instrumentation-vertexai>=2.0b0実際にインストールされたバージョン(pip list)
- Python: 3.12.4
- google-genai: 1.39.1
- langfuse: 3.5.2
- opentelemetry-instrumentation-google-genai: 0.1.5
- opentelemetry-instrumentation-vertexai: 0.1.11
- python-dotenv: 1.1.1エージェント構成#
今回は、ADK Multi-tool Agent Sample をベースに、東京の天気と現在時刻を取得するシンプルなエージェントを構築しました。2つのツール(get_weatherとget_current_time)を持つエージェントです。
from datetime import datetime
from zoneinfo import ZoneInfo
from google.adk.agents import Agent
def get_weather(city: str) -> dict:
"""指定された都市の天気情報を取得"""
if city.lower() == "東京":
return {
"status": "success",
"report": (
"東京の天気は晴れで、気温は25度です。"
),
}
else:
return {
"status": "error",
"error_message": f"'{city}'の天気情報は利用できません。",
}
def get_current_time(city: str) -> dict:
"""指定された都市の現在時刻を取得"""
if city.lower() == "東京":
tz_identifier = "Asia/Tokyo"
else:
return {
"status": "error",
"error_message": (
f"'{city}'のタイムゾーン情報は利用できません。"
),
}
tz = ZoneInfo(tz_identifier)
now = datetime.now(tz)
report = (
f'{city}の現在時刻は{now.strftime("%Y-%m-%d %H:%M:%S %Z%z")}です。'
)
return {"status": "success", "report": report}
root_agent = Agent(
name="weather_time_agent",
model="gemini-2.5-flash-lite",
description=(
"東京の天気と現在時刻を取得するエージェントです。"
),
instruction=(
"東京の天気と現在時刻を取得するエージェントです。"
),
tools=[get_weather, get_current_time],
)A2Aの実装パターン#
A2Aには主に2つの実装パターンがあります。「Exposingパターン」と「Consumingパターン」です。今回は両方の方法でエージェントを実装し、トレースの挙動を確認しました。
共通設定#
両パターンで共通して使用するサーバー設定は以下の通りです。
import uvicorn
from google.adk.agents import ADKAgentExecutor
from a2a.server import A2AStarletteApplication, DefaultRequestHandler
from a2a.storage import InMemoryTaskStore
request_handler = DefaultRequestHandler(
agent_executor=ADKAgentExecutor(agent=root_agent),
task_store=InMemoryTaskStore(),
)
server = A2AStarletteApplication(
agent_card=public_agent_card,
http_handler=request_handler,
)
uvicorn.run(server.build(), host='0.0.0.0', port=9999)Exposingパターン#
Exposingパターンは、自作のエージェントをA2Aプロトコルで公開する方式です。自社で開発したエージェントを外部に公開し、他のチームやシステムが利用できるエージェントサービスを提供する際に使用します。
A2Aサーバーは、エージェントのメタデータを記述したAgent Cardを自動的に生成し、well-known URLで公開します。クライアントはこのAgent Cardを参照することで、エージェントの機能や入出力形式を理解できます。
from google.adk.a2a import to_a2a
# ADKエージェントをA2Aサーバーとして公開
a2a_app = to_a2a(root_agent, port=8001)実装の詳細は、ADK公式ドキュメントのクイックスタート(Exposing) を参考にしました。
Consumingパターン#
Consumingパターンは、既存のA2Aエージェントをリモートから利用する方式です。外部ベンダーが提供するA2Aエージェントを活用する際に使用します。
from google.adk.a2a import RemoteA2aAgent, AGENT_CARD_WELL_KNOWN_PATH
from google.adk.agents import Agent
weather_time_agent = RemoteA2aAgent(
name="weather_time_agent",
description=(
"東京の天気と現在時刻を取得するエージェントです。"
),
agent_card=f"http://localhost:8001/a2a/weather_time_agent{AGENT_CARD_WELL_KNOWN_PATH}",
)
root_agent = Agent(
model="gemini-2.5-flash-lite",
name="root_agent",
instruction=(
"日本語で回答して"
),
sub_agents=[weather_time_agent],
)実装の詳細は、ADK公式ドキュメントのクイックスタート(Consuming) を参考にしました。
Agent Card#
Agent Cardは、エージェントのメタデータを定義するJSONファイルで、Consumingパターンにおいて重要な役割を果たします。以下は今回使用したAgent Cardの例です。
{
"capabilities": {},
"defaultInputModes": ["text/plain"],
"defaultOutputModes": ["text/plain"],
"description": "東京の天気と現在時刻を取得するエージェントです。",
"name": "weather_time_agent",
"skills": [
{
"id": "weather_time_checking",
"name": "Weather and Time Checking",
"description": "東京の天気と現在時刻を取得します。",
"tags": ["weather", "time"]
}
],
"url": "http://localhost:8001/a2a/weather_time_agent",
"version": "1.0.0"
}Langfuseでのトレース取得#
Langfuseは、LLMアプリケーションのトレーシングと評価に特化したオープンソースツールです。OpenTelemetryと統合されており、A2A × ADKエージェントのトレースを簡単に取得できます。
基本的な実装方法#
A2AやADKを使用する場合、Langfuseでトレースを取得する方法はシンプルで、Langfuse Clientを初期化するだけで、自動的にトレースが収集されます。※LANGFUSE_HOSTなどの環境変数はあらかじめ設定しておきます
from langfuse import get_client
langfuse = get_client()これだけで、A2AやADKが生成するすべてのspanが自動的にLangfuseに送信されます。明示的にspanの設定を記述する必要がないのは、OpenTelemetryのインストルメンテーションライブラリが自動的にspanを生成するためです。
ExposingパターンとConsumingパターンの違い#
ExposingとConsuming両方のパターンでトレースを取得しましたが、構造や内容に差は見受けられませんでした。
バッチ処理での結果#
まず、バッチ処理でのトレース結果を見てみましょう。
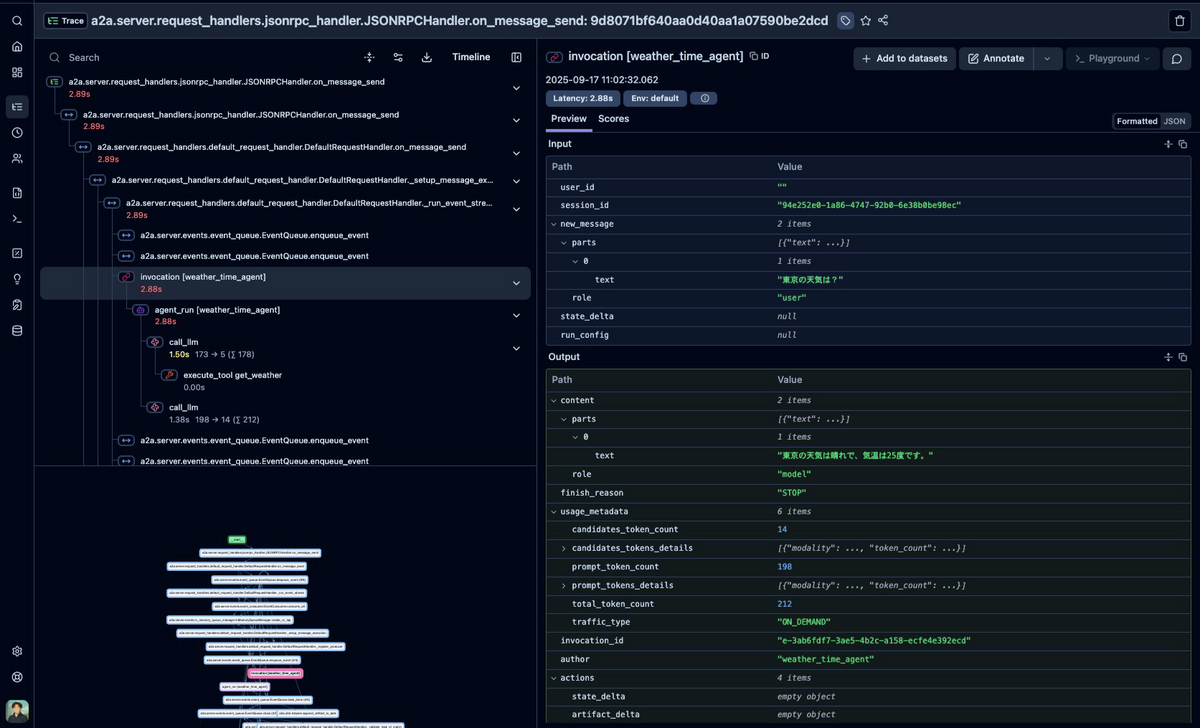
トレース構造の特徴#
バッチ処理では、1つのトレース内に大量のspanが生成されます。具体的には以下の構成になっています。
- A2A関連のspan: 約35個
- ADK関連のspan: 約5個
- 合計: 約40個のspan
これらのspanは階層的に配置され、エージェントの処理フローを詳細に記録しています。
ストリーミング処理での結果#
次に、ストリーミング処理でのトレース結果を確認します。
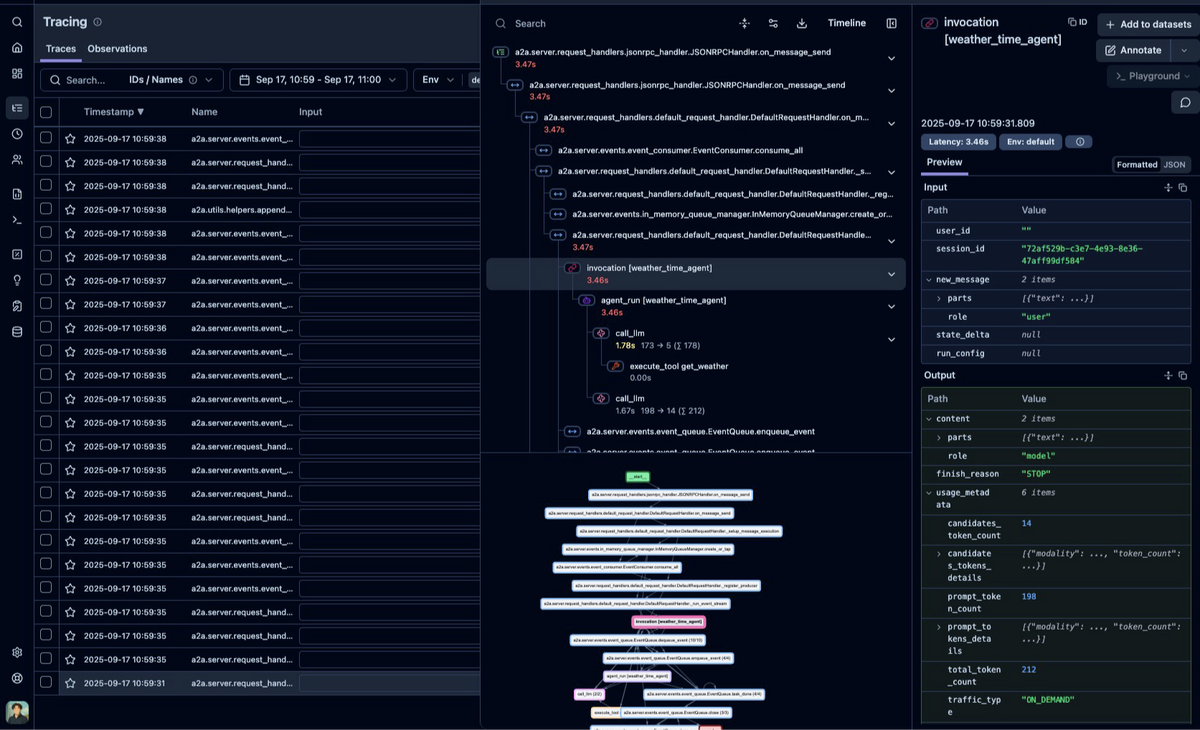
トレース構造の特徴#
ストリーミング処理では、バッチ処理とは大きく異なるトレース構造が生成されます。
複数の大きなトレース: それぞれがストリーミングレスポンスの断片に対応
- 各トレースには約40個のspan(A2A: 35個 + ADK: 5個)が含まれる
約30個の独立した小さなトレース:
- 各トレースのspan数は1~3個と少ない
- バッチ処理の各spanがトレースとして独立したような構造です
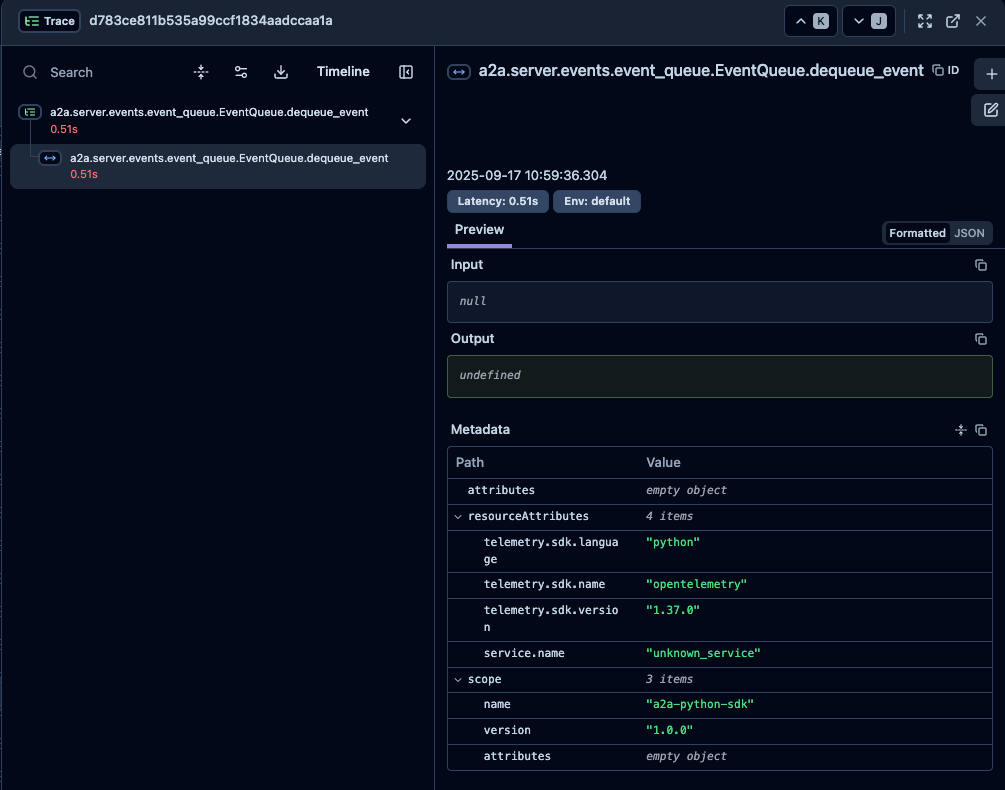
バッチとの違い#
spanの名前から判断すると、ストリーミング処理ではバッチ処理の各処理単位が独立したトレースになっていることがわかります。これは、ストリーミングの性質上、処理が分割されて実行されるためです。
バッチ vs ストリーミングの数値比較
| 項目 | バッチ | ストリーミング |
|---|---|---|
| 大きなトレース数 | 1個 | 1個~ |
| 大きなトレース1つあたりのspan数 | 約40個 | 約40個 |
| 小さな独立トレース数 | 0個 | 約30個 |
トレース内容の詳細分析#
トレースの内容を詳しく見ていくと、いくつかの興味深い特徴が見えてきます。
EventQueue関連spanの多さ#
トレースを観察すると、その大半をEventQueue関連のspanが占有していることがわかります。生成AIのリクエスト/レスポンス以外の処理で、膨大な数のspanが生成されています。
これらのspanは、A2AやADKの内部処理に関連しています。詳細な動作については、ライブラリの実装コードを参照する必要がありますが、イベント駆動型のアーキテクチャによる処理フローであることが考えられます。
EventQueue.deque_event の連続発生#
特に注目すべき点として、0.5秒継続するEventQueue.deque_eventspanが連続で発生しています。これは処理待ちやイベントキューの処理に起因すると推測されます。
重要な注意点として、実際のエージェントのレスポンス速度は速い可能性があります。 しかし、イベント処理が具体的に何を行っているか不明なため、LangfuseのUIに表示されるLatencyの値は、その内部処理時間を含んで大きくなってしまいます。この現象が、パフォーマンス分析を複雑にする要因の一つです。
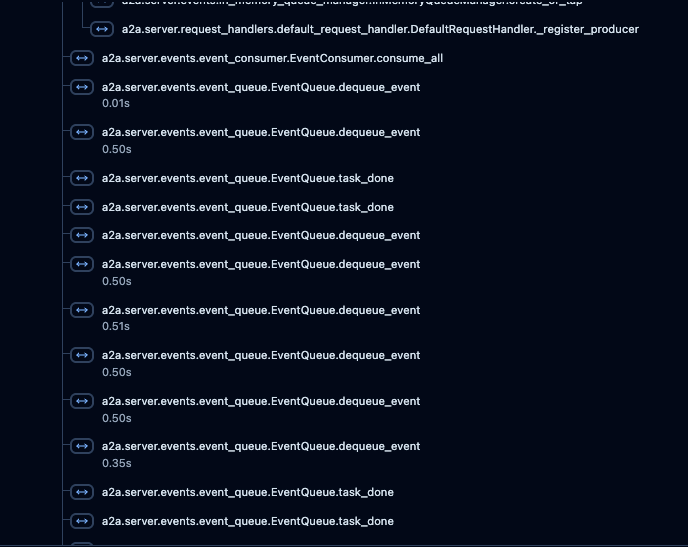
観測からの示唆#
A2A × ADKのトレース構造を観察した結果、A2A層は内部イベント処理が非常に詳細に出力されることが分かりました。これはA2Aの可視化が成功している証拠ですが、一方でLLM Ops的観点では情報過多となり、分析効率を下げる要因にもなります。
具体的には:
A2A関連のspanが34~35個と非常に多く、トレース全体の大部分を占める
LLMの推論処理やツール実行といった、アプリケーションレベルで重要な情報が埋もれてしまう
EventQueueの内部処理など、通常のデバッグでは不要な詳細情報が大量に含まれる
そこで次に、「A2Aの内部動作を理解した上で、どこまで観測すべきか」という「観測粒度の設計」を紹介します。
Cloud Traceでのトレース取得#
Cloud Traceは、Google Cloudが提供する分散トレーシングサービスです。OpenTelemetryと統合されており、A2A × ADKエージェントのトレースをGoogle Cloudの観測可能性プラットフォームに送信できます。
実装方法#
Cloud Traceを使用するには、OpenTelemetryの初期化とGoogle Cloud Observabilityの設定が必要です。Google Cloud 公式 ドキュメント に従って実装しました。
import google.auth
import google.auth.transport.requests
import grpc
from opentelemetry import trace, logs, metrics
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk._logs import LoggerProvider
from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
from opentelemetry.exporter.cloud_logging import CloudLoggingExporter
from opentelemetry.sdk.metrics import MeterProvider
from opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader
from opentelemetry.exporter.cloud_monitoring import CloudMonitoringMetricsExporter
from opentelemetry.sdk.resources import Resource
from opentelemetry.semconv.resource import ResourceAttributes
from opentelemetry.instrumentation.vertexai import VertexAIInstrumentor
from opentelemetry.instrumentation.google_genai import GoogleGenAiSdkInstrumentor
from opentelemetry.exporter.otlp.proto.grpc._auth import AuthMetadataPlugin
SERVICE_NAME = ResourceAttributes.SERVICE_NAME
# OpenTelemetry初期化
def initialize_opentelemetry() -> None:
"""OpenTelemetryの初期化とGoogle Cloud Observabilityの設定"""
credentials, project_id = google.auth.default()
resource = Resource.create(
attributes={
SERVICE_NAME: "multi-tool-agent",
# The project to send spans to
"gcp.project_id": project_id,
}
)
# Set up OTLP auth
request = google.auth.transport.requests.Request()
auth_metadata_plugin = AuthMetadataPlugin(credentials=credentials, request=request)
channel_creds = grpc.composite_channel_credentials(
grpc.ssl_channel_credentials(),
grpc.metadata_call_credentials(auth_metadata_plugin),
)
# Set up OpenTelemetry Python SDK
tracer_provider = TracerProvider(resource=resource)
tracer_provider.add_span_processor(
BatchSpanProcessor(
OTLPSpanExporter(
credentials=channel_creds,
endpoint="https://telemetry.googleapis.com:443/v1/traces",
)
)
)
trace.set_tracer_provider(tracer_provider)
logger_provider = LoggerProvider(resource=resource)
logger_provider.add_log_record_processor(
BatchLogRecordProcessor(CloudLoggingExporter())
)
logs.set_logger_provider(logger_provider)
reader = PeriodicExportingMetricReader(CloudMonitoringMetricsExporter())
meter_provider = MeterProvider(metric_readers=[reader], resource=resource)
metrics.set_meter_provider(meter_provider)
# Load instrumentors
# ADK uses Vertex AI and Google Gen AI SDKs.
VertexAIInstrumentor().instrument()
GoogleGenAiSdkInstrumentor().instrument()
print(f"OpenTelemetryが初期化されました。Google Cloud Project ID: {project_id}")
# OpenTelemetryの初期化を実行
initialize_opentelemetry()この設定により、A2A × ADKエージェントのすべてのトレースがCloud Traceに送信されます。
取得結果#
Cloud Traceで取得したトレースを確認してみましょう。
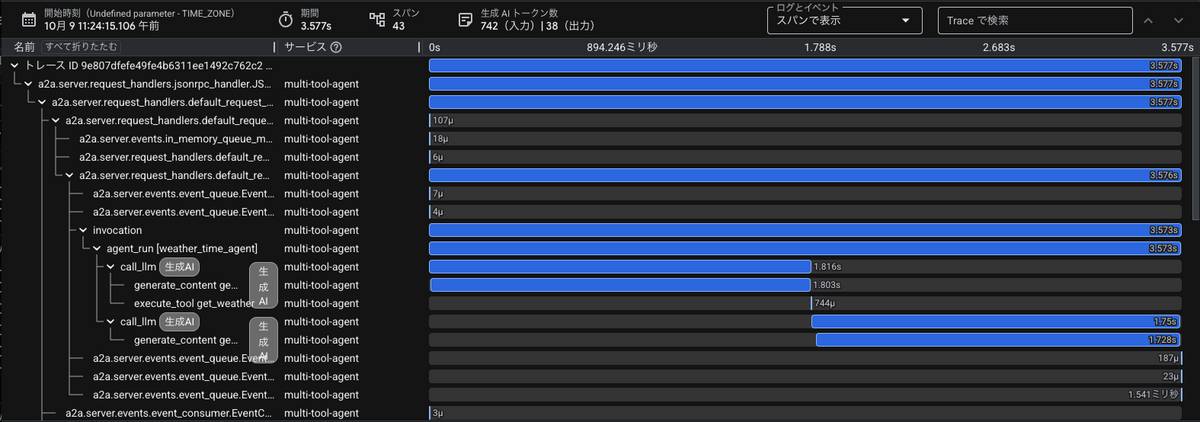
- バッチ処理: 1つのトレースに大量のspan(39個)
- ストリーミング処理: 複数の大きなトレース + 多数の小さな独立トレース
OpenTelemetryという共通の基盤を使用しているため、同じトレースデータが異なるUIで表示されているだけです。それぞれのツールの利点を活かして、目的に応じて使い分けることができます。
観測粒度の最適化(フィルタリング)#
ここまで見てきたように、A2A × ADKエージェントは非常に多くのspanを生成します。これは詳細な情報を得られる反面、重要なspanが埋もれてしまうという問題があります。
課題#
具体的な課題は以下の通りです:
- A2A関連のspan(34~35個)がトレースを複雑化
- ADKの重要なspan(5個)が埋もれてしまう
- 分析やデバッグの効率が低下
例えば、LLMの推論処理だけを見たい場合、A2Aの内部処理に関する膨大なspanは不要です。このような場合、Langfuseの計測スコープフィルタリング機能が非常に有用です。
Langfuseの計測スコープフィルタリング機能#
計測スコープとは#
計測スコープ(Instrumentation Scope) は、インストルメンテーションライブラリがspanに付与するメタデータです。どのライブラリがspanを生成したかを識別するための情報で、Langfuse UIでは metadata.scope.name として表示されます。
今回のA2A × ADKエージェントでは、主に以下の計測スコープが使用されています:
- a2a-python-sdk: A2A関連のspan
- gcp.vertex.agent: ADK関連のspan
この情報を活用することで、特定のライブラリが生成したspanをフィルタリングできます。
フィルタリングの実装#
基本的な設定方法#
Langfuseのクライアント初期化時に、blocked_instrumentation_scopesパラメータを指定することで、特定の計測スコープのspanをフィルタリングできます。
from langfuse import Langfuse
# フィルタリング機能使用時
langfuse = Langfuse(
blocked_instrumentation_scopes=["a2a-python-sdk", "gcp.vertex.agent"]
)A2Aのみを削除のパターンの場合#
最も実用的なパターンは、A2A関連のspanのみを削除する方法です。
A2Aの内部処理はOpenTelemetryで詳細にトレースされますが、LLM推論やADKツール呼び出しの可視化を主目的とする場合は、A2Aの内部spanを除外した"要約的トレース"が実務上最適です。これはA2Aの動作を十分理解した上で、可視化の粒度を最適化するというアプローチです。
langfuse = Langfuse(blocked_instrumentation_scopes=["a2a-python-sdk"])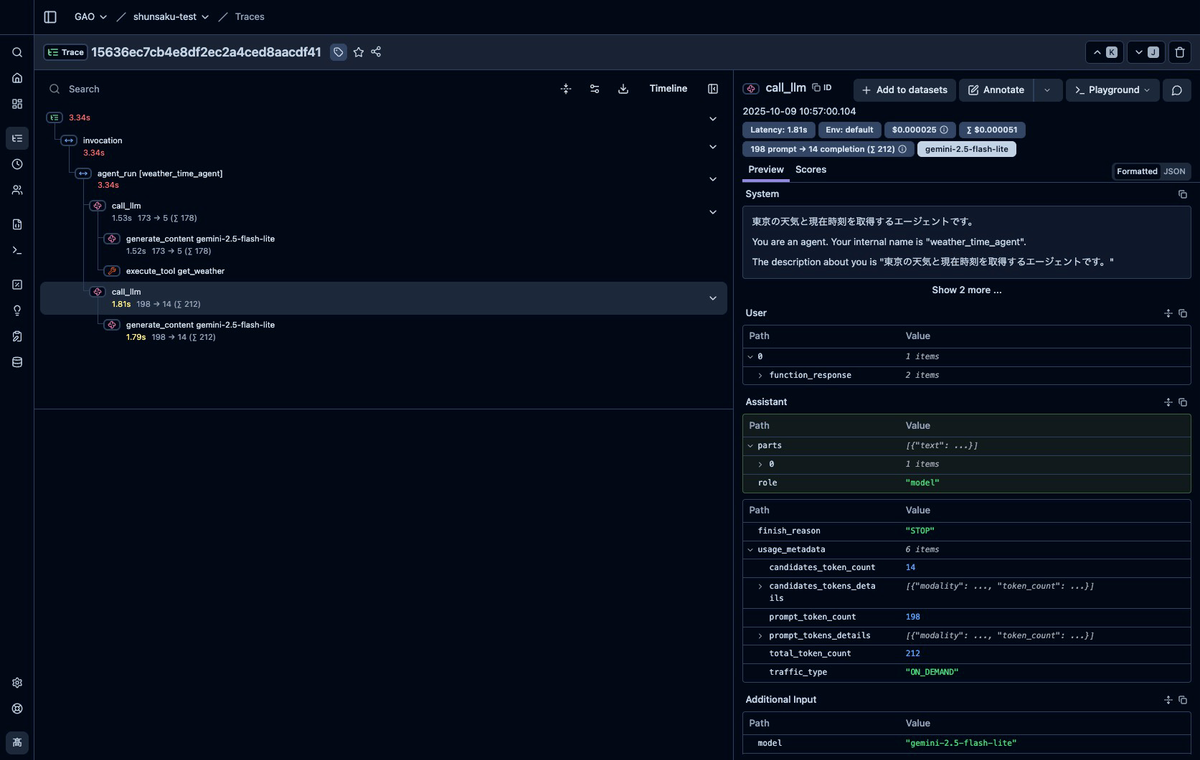
- ADKの5つのspanのみが残り、シンプルなトレースになります
- LLMの推論処理や各ツールの実行状況が明確に可視化されます
- ただし、これらのspanが名前のないトレースの子として配置されます
- トレース一覧で区別しにくくなるという問題がありますが、LLMの処理部分が見えているため、多くの場合で有効な方法です
フィルタリングの注意点#

トレースツリーの破壊問題#
Langfuse公式ドキュメント には、以下の警告が記載されています:
「ブロックされたライブラリとブロックされていないライブラリの範囲がネストされている場合、特定のライブラリをブロックするとトレースツリーの関係が壊れる可能性がある」
これは、A2A × ADKのようにライブラリのspanがネストされている場合に発生する問題です。親spanがフィルタリングされると、子spanが孤立してしまうのです。
名前のないトレース問題#
親spanがフィルタリングされたため、子spanが孤立し、名前のないトレースの子として配置されてしまいます。これにより、トレース一覧で区別しにくくなります。
推奨されるフィルタリングパターン#
目的に応じて、以下のパターンから選択することをおすすめします:
フィルタリングパターンと結果:
| パターン | A2A span | ADK span | トレース構造 | 用途 |
|---|---|---|---|---|
| フィルタなし | ◯ | ◯ | 正常 | 全体把握・詳細デバッグ |
| A2Aのみ削除 | × | ◯ | 破壊 ※1 | LLM処理分析(推奨) |
| ADKのみ削除 | ◯ | × | 正常 | LLM処理が見えないため非推奨 |
| 両方削除 | × | × | - ※2 | 手動トレース設定時(高度な用途) |
※1 子spanが孤立し、「名前のないトレース」の子になる。
※2 自動生成トレースが無効になる。
パターン別の詳細#
1. フィルタなし(デフォルト)
- すべてのspanを含めて全体像を把握したい場合
- システム全体のフローを理解したい初期段階
- 詳細なデバッグが必要な場合
2. A2Aのみ削除(実用的)
- LLMの推論処理に焦点を当てたい場合
- ツールの実行状況を明確に可視化したい場合
- トレース構造は破壊され名前のないトレースになりますが、実用上は妥協可能な範囲
3. ADKのみ削除(非推奨)
- A2Aの内部処理を詳細に見たい場合
- ただし、LLMの処理部分が見えなくなるため、このパターンはあまり採用する意味がありません
4. 両方削除(高度な用途)
- 自動生成されるトレースを完全に無効化
- トレースの手動設定&送信ができるため、細かくトレースの中身を設定したい場合は一番推奨できるパターン
- より細かい粒度でトレースをカスタマイズしたい上級者向け
まとめ#
トレーシングのポイント#
A2A × ADKエージェントのトレーシングについて、以下の重要なポイントを確認しました:
Langfuse/Cloud Trace両方でOpenTelemetry経由の自動トレース取得が可能
- Langfuse Clientの初期化だけで、簡単にトレースが収集される
- インストルメンテーションライブラリによる自動span生成が機能
バッチとストリーミングで大きく異なるトレース構造
- バッチ: 1つのトレースに約39個のspan
- ストリーミング: 複数の大きなトレース + 約30個の小さな独立トレース
EventQueue関連のspanが大部分を占める
- トレースの大半がA2Aの内部処理に関連
- EventQueue.deque_eventの連続発生がLatency表示値に影響(実際のレスポンス速度とは別)
フィルタリング機能の活用#
Langfuseの計測スコープフィルタリング機能を効果的に活用するためのポイント:
計測スコープによるフィルタリングで不要なspanを削除可能
- blocked_instrumentation_scopesパラメータを使用
- a2a-python-sdkやgcp.vertex.agentなどの計測スコープを指定
トレース構造の破壊に注意が必要
- ネストされたspanの親をフィルタリングすると、子spanが孤立
- 名前のないトレース問題が発生する可能性
目的に応じた適切なフィルタリング設定を選択
- LLM処理分析: A2Aのみ削除(最も実用的)
- 全体把握: フィルタなし
- 高度なカスタマイズ: 両方削除 + 手動トレース設定
今後の展望と注意事項#
A2A × ADKエージェントのトレーシングには、まだ解明されていない部分もあります:
EventQueueの詳細な動作解明
- なぜこれほど多くのspanが生成されるのか
- 内部処理の最適化の可能性
ストリーミング時のspan分割メカニズムの理解
- どのようなロジックでトレースが分割されるのか
- パフォーマンスへの影響
より効率的なトレース分析手法の確立
- カスタムメトリクスの追加
- トレースの可視化方法の改善
本記事の内容は現時点(2025年10月)での実装に基づいており、将来的にライブラリのアップデートによってトレース構造やspan数が変わる可能性があることにご注意ください。
A2A × ADKエージェントの観測可能性を高めることで、より効率的なシステム開発とデバッグが可能になります。本記事で紹介したトレーシングとフィルタリングの技術が、皆さんのエージェント開発の一助となれば幸いです。
参考資料#
本記事の実装にあたり、以下の公式ドキュメントを参考にしました: