LangfuseにおけるPIIマスキングの必要性#
チャットボットのようなアプリケーションでは、ユーザーが意図せず個人情報(PII)を入力してしまう可能性があります。個人情報保護の観点から、これらの情報がLangfuseのトレースにそのまま出力されるのは望ましくありません。
そこで、トレース上で個人情報をマスキングした状態で確認できるよう、どのような手段が考えられるか検証しました。
個人情報(PII)の定義と具体例#
具体的に個人情報(PII) に該当する項目は、一般的に以下のものが挙げられます。
- 氏名
- 住所
- 電話番号
- メールアドレス
- 顔写真
- 身分証番号(運転免許証、パスポートなど)
- 生年月日
- 社会保障番号
- クレジットカード情報
- 銀行口座情報
今回はテキスト入力ベースのアプリケーションを想定しているため、顔写真のような画像データは検証対象外とします。
LangfuseにおけるPIIマスキング手法の検討#
Langfuseの公式サイトで紹介されている Masking of Sensitive LLM Data を参考に、マスキング手法を検討します。
氏名や住所は正規表現での対応が難しいため、今回は Example 2 で紹介されている llm-guard を試してみました。
氏名や住所のような複雑な情報は正規表現での対応が難しいため、今回はExample 2で紹介されているllm-guardを試用しました。
今回試用したllm-guardのAnonymize機能は、現在以下の個人情報(PII)の検出に対応しています。
- クレジットカード
- 人名
- 電話番号
- URL
- メールアドレス
- IPアドレス
- UUID
- 米国社会保障番号(SSN)
- 暗号資産ウォレット番号
- IBANコード
今回マスキング対象として期待している項目は以下の通りです。
- 氏名
- 生年月日
- 住所
- 電話番号
- メールアドレス
- 運転免許証番号
- パスポート番号
- 社会保障番号
- クレジットカード情報
- カード番号
- 有効期限
- セキュリティコード
- 銀行口座情報
- 銀行名
- 支店名
- 口座番号
PIIマスキングのテスト方法#
簡単なコードを用いて、プロンプトの入力とLLMの回答を模擬的に生成し、それぞれをLangfuseに登録する形式でテストを行いました。
アプリケーションコード#
今回の検証では、PythonアプリケーションからLangfuseにトレースを投入するケースを対象としています。マスキング処理は、Langfuseの初期化時にmaskオプションに対して、処理を行う関数を設定することで実現できます。
vault = Vault()
def create_anonymize_scanner():
scanner = Anonymize(
vault=vault,
)
return scanner
def masking_function(data: any, **kwargs) -> any:
if isinstance(data, str):
scanner = create_anonymize_scanner()
sanitized_data, is_valid, score = scanner.scan(data)
return sanitized_data
return data
# テスト用の入力テキスト
input_text = """[[ダミーデータを含むプロンプト]]"""
# Langfuseの初期化
langfuse = Langfuse(
public_key="xxxxxxxxxxxxxxxxxxxxxxxx",
secret_key="xxxxxxxxxxxxxxxxxxxxxxxx",
host="http://xxxxxxxxxxxxxxxx",
mask=masking_function,
)
# LLM呼び出しのトレース
with langfuse.start_as_current_generation(
name=f"test_step",
input=input_text,
) as generation:
# LLMからの実際の出力を格納
response_content = input_text # 現在はダミーデータを使用
generation.update(output=response_content)テストデータ#
テスト用のプロンプトとLLMの出力結果として、Cursorを用いて上記の個人情報(PII)具体例を含むダミーデータを以下の通り生成しました。インプットとアウトプットの双方に個人情報が含まれるとトレース上での問題となるため、今回は同じテストデータを利用し、両方のデータにマスキングが適用されるかを確認します。
私の個人情報は以下の通りです:
氏名:山田 太郎Name: Taro Yamada
生年月日:1985年3月15日Birthday: March 15, 1985
住所:東京都新宿区西新宿2-8-1Address: 2-8-1 Nishi-Shinjuku, Shinjuku-ku, Tokyo, Japan
電話番号:03-1234-5678 / 090-9999-8888Phone: +81-3-1234-5678 / +81-90-9999-8888
メールアドレス:taro.yamada@example.comEmail: taro.yamada@example.com
運転免許証番号:123456789012Driver’s License: DL-123456789012
パスポート番号:TK1234567Passport Number: TK1234567
社会保障番号:987-65-4321Social Security Number: 987-65-4321
クレジットカード情報:
- カード番号:4111-2222-3333-4444
- 有効期限:12/25
- セキュリティコード:123
Credit Card Information:
- Card Number: 4111-2222-3333-4444
- Expiry Date: 12/25
- Security Code: 123
銀行口座情報:
- 銀行名:みずほ銀行
- 支店名:新宿支店
- 口座番号:1234567
Bank Account Information:
- Bank Name: Mizuho Bank
- Branch: Shinjuku Branch
- Account Number: 1234567
最低限の引数での動作確認#
上記のコードを実行したところ、何らかの置換が行われていることが確認できました。
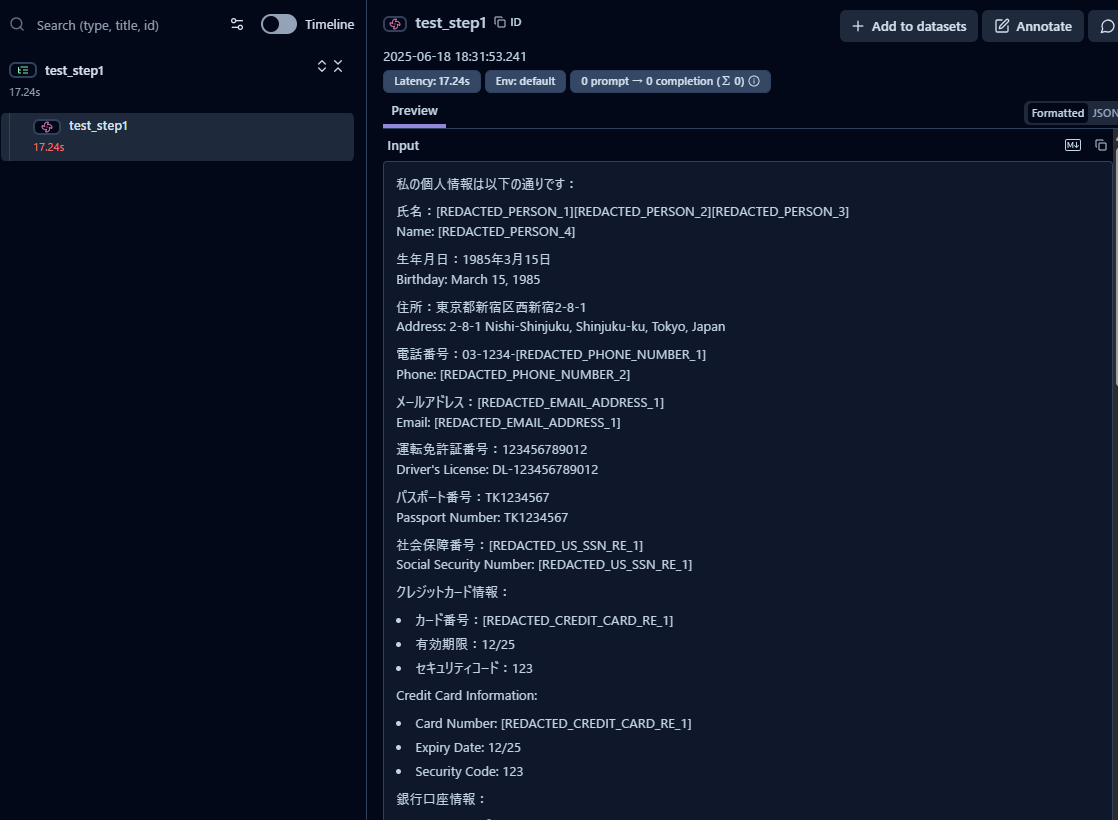
検証結果:インプットとアウトプットの比較#
インプットの結果をpt1_input.txt、アウトプットの結果をpt1_output.txt として比較しました。

inputとoutputのいずれに渡した場合でも、マスキング処理が適応されていることが確認できました。
検証結果:各個人情報の検出状況#
プロンプトとして与えた各個人情報について、どのように処理されたかひとつずつ確認していきます。
氏名:△#
氏名:[REDACTED_PERSON_1][REDACTED_PERSON_2][REDACTED_PERSON_3]Name: [REDACTED_PERSON_4]
検知・置換自体は行われていますが、日本語名が意図せず三分割されている点が課題です。
生年月日:×#
住所:×#
これらはllm-guardの現在の検出対象外のため、想定通りの結果です。
電話番号:×#
電話番号:03-1234-[REDACTED_PHONE_NUMBER_1]Phone: [REDACTED_PHONE_NUMBER_2]
2種類の電話番号を「/」区切りで記載していましたが、一つの電話番号とみなされているようです。いずれにしても、日本の電話番号形式への対応はまだ課題があります。
メールアドレス:○#
運転免許証番号:×#
パスポート番号:×#
社会保障番号:○#
これらの項目については、当初の想定通りの検出結果となりました(運転免許証番号、パスポート番号は検出対象外のため×、メールアドレス、社会保障番号は検出対象のため○)。
クレジットカード情報:△#
クレジットカード情報:カード番号:[REDACTED_CREDIT_CARD_RE_1]有効期限:12/25セキュリティコード:123
カード番号は問題なく検出できましたが、有効期限やセキュリティコードはマスキングされませんでした。ドキュメント ではVisa、American Express、Diners Clubに対応とあるため、他のカード会社への対応状況も確認が必要です。
銀行口座情報:×#
こちらもllm-guardの現在の検出対象外のため、想定通りの結果です。
各種設定や検出モデルの変更による検証#
オプションの設定や検出に利用するモデルを変更することにより、対応している項目に関しては精度が向上する可能性があると考え、合わせて確認してみました。
日本語設定の試行#
Anonymizeの言語設定は標準では英語となっています。こちらを日本語に変更可能か試行しました。
しかし、llm-guardが現在サポートしているのは英語(’en’)と中国語(‘zh’)のみであることが確認されました。このため、日本語のPII検出において、言語設定によるアプローチは現状では利用できません。
recognizer_confの変更による比較検証#
Anonymizeでは、recognizer_confパラメータで検出モデルを指定できます。コードを以下のように変更し、llm_guard.input_scanners.anonymize_helpers で定義されているモデルを順に試行します。
scanner = Anonymize(
vault=vault,
recognizer_conf=[[ ここの値を変更 ]]
)定義されているモデルは以下の7種類になります。
- BERT_BASE_NER_CONF(dslim/bert-base-NER)
- BERT_LARGE_NER_CONF(dslim/bert-large-NER)
- BERT_ZH_NER_CONF(gyr66/bert-base-chinese-finetuned-ner)
- DISTILBERT_AI4PRIVACY_v2_CONF(Isotonic/distilbert_finetuned_ai4privacy_v2)
- DEBERTA_AI4PRIVACY_v2_CONF(Isotonic/deberta-v3-base_finetuned_ai4privacy_v2)
- MDEBERTA_AI4PRIVACY_v2_CONF(Isotonic/mdeberta-v3-base_finetuned_ai4privacy_v2)
- DEBERTA_LAKSHYAKH93_CONF(lakshyakh93/deberta_finetuned_pii)
各モデルにおいて、先に試行したデフォルト設定時の差分に重点を置いて確認していきます。
デフォルト設定時にマスキングされなかったものについては、「-」で表示しています。
(マスキングの数値のみが異なっている場合は、同様の検出が行われたと判断しています)
| 氏名(日本語) | 氏名(英語) | 生年月日 | 住所 | 電話番号(日本) | 電話番号(海外) | メールアドレス | 運転免許証番号 | パスポート番号 | 社会保障番号 | クレジットカード(カード番号) | クレジットカード(カード番号以外) | 銀行口座情報 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| デフォルト設定(参考) | [REDACTED_PERSON_1][REDACTED_PERSON_2][REDACTED_PERSON_3] | [REDACTED_PERSON_4] | - | - | 03-1234-[REDACTED_PHONE_NUMBER_1] | [REDACTED_PHONE_NUMBER_2] | [REDACTED_EMAIL_ADDRESS_1] | - | - | [REDACTED_US_SSN_RE_1] | [REDACTED_CREDIT_CARD_RE_1] | - | - |
| BERT_BASE_NER_CONF | 山田 太郎 | [REDACTED_PERSON_1][REDACTED_PERSON_2]mada | - | - | 03-1234-5678 / 090-9999-8888 | [REDACTED_PHONE_NUMBER_1] / [REDACTED_PHONE_NUMBER_2] | [REDACTED_EMAIL_ADDRESS_1] | - | - | [REDACTED_US_SSN_RE_1] | [REDACTED_CREDIT_CARD_RE_1] | - | - |
| BERT_LARGE_NER_CONF | 山田 太郎 | [REDACTED_PERSON_3] | - | - | 03-1234-5678 / 090-9999-8888 | [REDACTED_PHONE_NUMBER_1] / [REDACTED_PHONE_NUMBER_2] | [REDACTED_EMAIL_ADDRESS_1] | - | - | [REDACTED_US_SSN_RE_1] | [REDACTED_CREDIT_CARD_RE_1] | - | - |
| BERT_ZH_NER_CONF | [REDACTED_PERSON_4] | Taro Yamada | - | - | 03-1234-5678 / 090-9999-8888 | [REDACTED_PHONE_NUMBER_1] / [REDACTED_PHONE_NUMBER_2] | [REDACTED_EMAIL_ADDRESS_1] | - | - | [REDACTED_US_SSN_RE_1] | [REDACTED_CREDIT_CARD_RE_1] | - | - |
| DISTILBERT_AI4PRIVACY_v2_CONF | 山田 太郎 | Taro Yamada | - | - | 03[REDACTED_PHONE_NUMBER_3] | [REDACTED_PHONE_NUMBER_1] / [REDACTED_PHONE_NUMBER_2] | [REDACTED_EMAIL_ADDRESS_1] | 運転免許証番号:[REDACTED_PHONE_NUMBER_4] Driver's License: DL-[REDACTED_PHONE_NUMBER_5]12 | - | [REDACTED_US_SSN_RE_1] | [REDACTED_CREDIT_CARD_RE_1] | - | - |
| DEBERTA_AI4PRIVACY_v2_CONF | [REDACTED_PERSON_5][REDACTED_PERSON_6][REDACTED_PERSON_7] | [REDACTED_PERSON_3] | - | - | 03-1234-[REDACTED_PHONE_NUMBER_6] | [REDACTED_PHONE_NUMBER_7] | [REDACTED_EMAIL_ADDRESS_1] | - | - | [REDACTED_US_SSN_RE_1] | [REDACTED_CREDIT_CARD_RE_1] | - | - |
| MDEBERTA_AI4PRIVACY_v2_CONF | [REDACTED_PERSON_8] 太郎 | Taro [REDACTED_PERSON_9] | - | - | [REDACTED_PHONE_NUMBER_8] / [REDACTED_PHONE_NUMBER_9] | [REDACTED_PHONE_NUMBER_1] / [REDACTED_PHONE_NUMBER_2] | [REDACTED_EMAIL_ADDRESS_1] | - | - | [REDACTED_US_SSN_RE_1] | [REDACTED_CREDIT_CARD_1] | - | - |
| DEBERTA_LAKSHYAKH93_CONF | 山田 太郎 | [REDACTED_PERSON_1][REDACTED_PERSON_2][REDACTED_PERSON_3] | [REDACTED_IBAN_CODE_1] | [REDACTED_CRYPTO_2] | 03-1234-5678 / 090-9999-8888 | [REDACTED_PHONE_NUMBER_1] / [REDACTED_PHONE_NUMBER_2] | [REDACTED_EMAIL_ADDRESS_1] Email: [REDACTED_EMAIL_ADDRESS_2] | - | [REDACTED_IBAN_CODE_2] Passport Number: TK1234567 | 社会[REDACTED_IBAN_CODE_3] Social Security Number: [REDACTED_US_SSN_RE_1] | [REDACTED_CREDIT_CARD_RE_1] | - | [REDACTED_CRYPTO_3]- [REDACTED_CRYPTO_4] [REDACTED_IP_ADDRESS_2] |
各モデルの比較検証結果
BERT_BASE_NER_CONF
氏名:山田 太郎Name: [REDACTED_PERSON_1][REDACTED_PERSON_2]mada
日本語氏名はマスキングされず、英語氏名は部分的にマスキングされる形になりました。
電話番号:03-1234-5678 / 090-9999-8888Phone: [REDACTED_PHONE_NUMBER_1] / [REDACTED_PHONE_NUMBER_2]
電話番号も全てマスキングされない結果です。
ただし、海外向けフォーマットにおいては、適切に2つ分として判断されているようです。
BERT_LARGE_NER_CONF
氏名:山田 太郎Name: [REDACTED_PERSON_3]
日本語氏名はマスキングされませんでしたが、英語氏名は綺麗にマスキングされました。
電話番号:03-1234-5678 / 090-9999-8888Phone: [REDACTED_PHONE_NUMBER_1] / [REDACTED_PHONE_NUMBER_2]
電話番号については、BERT_BASE_NER と同じ形になりました。
BERT_ZH_NER_CONF
氏名:[REDACTED_PERSON_4]Name: Taro Yamada
日本語氏名はマスキングされましたが、英語氏名はマスキングされませんでした。
中国語のNERモデルとなるため、漢字はうまく判別出来ているのかもしれません。
実際に採用できるかは、名前がひらがなのケースも一度確認する必要がありそうです。
電話番号:03-1234-5678 / 090-9999-8888Phone: [REDACTED_PHONE_NUMBER_1] / [REDACTED_PHONE_NUMBER_2]
こちらも電話番号については、BERT_BASE_NER と同じ形になりました。
DISTILBERT_AI4PRIVACY_v2_CONF
氏名:山田 太郎Name: Taro Yamada
日本語、英語共にマスキングされていません。
電話番号:03[REDACTED_PHONE_NUMBER_5]Phone: [REDACTED_PHONE_NUMBER_1] / [REDACTED_PHONE_NUMBER_2]
日本国内向けの電話番号はまだ適切に検知できていないようですが、こちらも海外向けフォーマットにおいては、適切に2つ分として判断されているようです。
運転免許証番号:[REDACTED_PHONE_NUMBER_6]Driver’s License: DL-[REDACTED_PHONE_NUMBER_7]12
電話番号として誤検出され、部分的にマスキングされています。
英語では末尾2文字がマスキングされておらず、日本語と英語で検出範囲が異なっているのも気になる点です。
DEBERTA_AI4PRIVACY_v2_CONF
置換後の数値に差異はあるものの、デフォルトで指定されているモデルのため、同じ形でマスキングされていました。
MDEBERTA_AI4PRIVACY_v2_CONF
氏名:[REDACTED_PERSON_8] 太郎Name: Taro [REDACTED_PERSON_9]
日本語氏名、英語氏名共に姓のみマスキングされています。
電話番号:[REDACTED_PHONE_NUMBER_8] / [REDACTED_PHONE_NUMBER_9]Phone: [REDACTED_PHONE_NUMBER_1] / [REDACTED_PHONE_NUMBER_2]
電話番号に関しては、国内・海外向けフォーマットともにマスキングされています。
DEBERTA_LAKSHYAKH93_CONF
他のモデルに比べ、誤検知が多く発生してます。
まず、1行目に記載している下記の文言ですが
私の個人情報は以下の通りです
以下の通り誤検知・置換されていました。
私の個人情報[REDACTED_CRYPTO_1]下の通りです:
その他、各項目についても以下の通り誤検出が多くなっていました。
氏名:山田 太郎Name: [REDACTED_PERSON_1][REDACTED_PERSON_2][REDACTED_PERSON_3]
日本語氏名がマスキングされておらず、英語氏名も3分割で検知されています。
[REDACTED_IBAN_CODE_1]
生年月日がIBANコードとして誤検出されています。
[REDACTED_CRYPTO_2]
住所が暗号通貨のウォレット番号として誤検出されています。
電話番号:03-1234-5678 / 090-9999-8888[REDACTED_IP_ADDRESS_1] [REDACTED_PHONE_NUMBER_1] / [REDACTED_PHONE_NUMBER_2]
日本語の番号がマスキングされていません。
海外向けフォーマットについては適切に検出されているように見えますが、関係のない「Phone:」がIPアドレスとして誤検出されています。
[REDACTED_EMAIL_ADDRESS_1]Email: [REDACTED_EMAIL_ADDRESS_2]
「メールアドレス:」部分もメールアドレスとして誤検出されています。
Driver’s License: DL-123456789012[REDACTED_IBAN_CODE_2]Passport Number: TK1234567
「パスポート番号:TK1234567」がIBANコードとして誤検出されています。
社会[REDACTED_IBAN_CODE_3]
社会保障番号が文言の途中からIBANコードとして誤検出されています。
[REDACTED_CRYPTO_3]- [REDACTED_CRYPTO_4] [REDACTED_IP_ADDRESS_2]
日本語の銀行口座情報が暗号通貨のウォレット番号、IPアドレスとして誤検知されています。
#
まとめ#
今回の検証では、llm-guardを用いたPIIマスキングの可能性を探りました。特に日本語の個人情報検出においては、現状では他の手法との併用や、より高精度なモデルの検証が必要となりそうです。