この記事のポイント#
前編では、Langfuse v3.158.0の “fulltext search” が実装上は部分一致検索であること、そして3層の検索アーキテクチャの全体像を解説しました。
後編では、PR #12578 のソースコードを詳しく読み、以下の2点を明らかにします。
- プロンプト編集画面のTextモードとChatモードで検索の挙動が異なること、特にChatモードではカウンターとハイライトが食い違うケースがあること
- サーバーサイド検索(ClickHouse / PostgreSQL)を含めた、日本語利用時の具体的な制約(Limitation)
→ 前編はこちら:「Langfuse v3.158.0の"fulltext search"を読み解く — その実態は部分一致検索だった」(リンク )
PR #12578のコードリーディング#
検索のエントリポイント:MessageSearchProvider#
検索機能のアーキテクチャは、React ContextベースのMessageSearchProviderを中心に構成されています。
Playground画面(web/src/features/playground/page/index.tsx)では、全ウィンドウをMessageSearchProviderで包み、各ウィンドウのpageIdを渡しています。Prompt Management側(PromptChatMessages.tsx)も同じMessageSearchProviderを使いますが、ページは1つだけです。つまり共通コンポーネントが両方の画面で再利用されています。
Cmd+F(Mac)/ Ctrl+F(Windows)のキーボードショートカットは、context.tsxのuseEffectでキャプチャされ、controller.openSearch()を呼び出します。このときcaptureRootRefでスコープを限定しているため、ページ全体のブラウザ検索を奪わず、メッセージ編集エリア内だけで機能します。
検索ロジックの核心:controller.tsのbuildMatches#
検索の実体はweb/src/components/ChatMessages/messageSearch/controller.tsにあります。buildMatches関数が全マッチを計算する部分です。
function buildMatches(state: MessageSearchState) {
const searchQuery = getCommittedQuery(state);
if (!searchQuery) return [];
const lowerQuery = searchQuery.toLocaleLowerCase();
const allMatches: MessageSearchMatch[] = [];
for (const [pageIndex, pageId] of state.pageIds.entries()) {
const pageMessages = state.pageMessagesById[pageId];
if (!pageMessages) continue;
for (const [messageIndex, message] of pageMessages.entries()) {
const text = getMessageSearchText(message);
if (!text) continue;
const lowerText = text.toLocaleLowerCase();
let from = lowerText.indexOf(lowerQuery);
while (from !== -1) {
// ... マッチオブジェクトを構築してallMatchesに追加
from = lowerText.indexOf(lowerQuery, from + Math.max(1, lowerQuery.length));
}
}
}
return allMatches;
}非常にシンプルです。toLocaleLowerCase()でケースフォールディングした後、indexOf()で部分文字列を探しています。150msのデバウンス(入力が一定時間途切れるまで処理の実行を遅延させる仕組み)付きで、タイピング中に検索が走りすぎないよう制御されています。
CodeMirrorとの連携と3つのマッチングシステム#
マッチ結果の表示は、controllerとCodeMirrorがそれぞれ独立に処理しています。さらにCodeMirror内部にも2つの仕組みがあり、合計3つのマッチングシステムが同時に動作しています。
| システム | 役割 | 正規化処理 | 大文字小文字 | |
|---|---|---|---|---|
| 1 | controller buildMatches | マッチカウンター(例: 1 / 3)とナビゲーション | なし(toLocaleLowerCase + indexOf) | 区別しない |
| 2 | @codemirror/search | 検索ハイライト(黄色) | NFKD + toLowerCase | 区別しない |
| 3 | highlightSelectionMatches | 選択テキストの類似箇所ハイライト(青色) | NFKDのみ | 区別する |
これらの正規化処理の違いが、後述するTextモード/Chatモードでの挙動差の原因になっています。
controllerの****syncActiveMatchTarget() はアクティブなマッチに対応するメッセージ行までスクロールし、selectCodeMirrorRange()でCodeMirrorのselection(カーソル選択範囲)を設定します。
applyCodeMirrorSearchQuery() は各エディタインスタンスに対して@codemirror/searchのsetSearchQueryエフェクトを発行します。ここでliteral: trueが設定されており、検索文字列中の.や*がメタ文字として解釈されず、入力そのままの文字列として扱われます。
日本語での検索挙動:コードから読み解く#
プロンプト編集画面には2つの検索がある#
プロンプト編集画面にはTextモードとChatモードがあり、それぞれ異なる検索メカニズムが動いています。
- Textモード:
PromptLinkingEditor→CodeMirrorEditorがそのまま使われ、enableSearchKeymapはデフォルトのtrueです。Cmd+Fを押すとCodeMirror組み込みの検索パネル(エディタ下端に表示)が開きます。これはPR #12578 のMessageSearchToolbarとは別の検索UIです - Chatモード:
PromptChatMessagesがMessageSearchProviderでラップされ、各メッセージのCodeMirrorEditorにはenableSearchKeymap={false}が設定されます。Cmd+Fを押すとPR #12578MessageSearchToolbar(メッセージ一覧上部の検索バー)が開きます
この2つは前述の3つのマッチングシステムのうち、どれが有効になるかが異なります。
Textモード:CodeMirror組み込み検索のNFKD正規化#
Textモードでは、表中の「#2 @codemirror/search」が有効になります。
@codemirror/search v6.6.0のソースコードを読むと、SearchCursorのコンストラクタで以下の処理が行われています。
// 常に適用されるベース正規化
const basicNormalize = x => x.normalize("NFKD");
// SearchCursorのコンストラクタ内
this.normalize = normalize ? x => normalize(basicNormalize(x)) : basicNormalize;caseSensitive: falseの場合、最終的な正規化関数はx => x.normalize("NFKD").toLowerCase()になります。
NFKD(Normalization Form Compatibility Decomposition) はUnicodeの互換分解を行う正規化形式で、全角英数字を半角英数字に分解します。たとえばL(U+FF2C、全角)はL(U+004C、半角)に分解されます。
つまりTextモードでは、全角/半角が相互にヒットします。
- クエリ「Langfuse」→ NFKD →
Langfuse→ toLowerCase →langfuse - ドキュメント「Langfuse」→ NFKD →
Langfuse→ toLowerCase →langfuse - → マッチする
実際にTextモードのプロンプト編集画面で確認したところ、全角英数字で検索しても半角英数字の文字列にヒットすることが確認できました。
Chatモード:カウンターとハイライトの食い違い#
Chatモード(PR #12578
MessageSearchToolbar)では、表中の「#1 controller」と「#3 highlightSelectionMatches」が動作し、「#2 @codemirror/search」は無効化されています(panelがnullのためDecoration.noneを返す)。
この組み合わせにより、以下のような挙動が確認されました。全角 「Langfuse」 で検索した結果です。
| ドキュメント中のテキスト | マッチカウンター(#1) | ハイライト(#3) |
|---|---|---|
| Langfuse(全角) | ヒットする | 青色(選択色) |
| Langfuse(半角・先頭大文字) | ヒットしない | 青色(選択色) |
| langfuse(半角・全小文字) | ヒットしない | なし |
| LANGFUSE(半角・全大文字) | ヒットしない | なし |
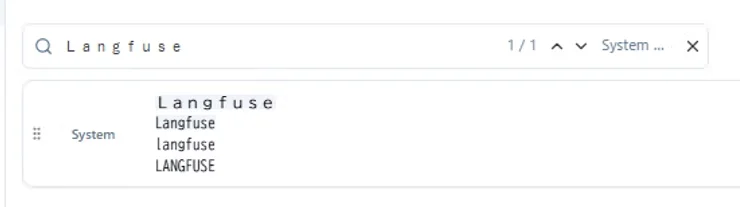
マッチカウンターは「1 / 1」(Langfuseのみ)。しかしLangfuseにも青色のハイライトが表示されています。
この食い違いの原因は、#1と#3の正規化処理の違いです。
- #1 controller:
toLocaleLowerCase()+indexOf()。NFKD正規化なし。全角Langfuseと半角Langfuseはコードポイントが異なるためマッチしない - #3
highlightSelectionMatches:controllerがLangfuseの位置にselectionを設定 →SearchCursorがNFKD正規化(toLowerCaseなし)で同じ文字列を探す → LangfuseはNFKD後にLangfuseになるため、ドキュメント中のLangfuseとマッチ。ただし大文字小文字を区別するためlangfuseやLANGFUSEにはマッチしない
Chatモードのcontroller側の日本語特性#
toLocaleLowerCase()はECMAScript仕様上、Unicode Case Foldingに基づいて大文字/小文字変換を行いますが、全角/半角の変換(全幅変換)は行いません。日本語のひらがな・カタカナ・漢字には大文字/小文字の区別がないため、この関数は実質的にパススルーになります。
indexOf()によるマッチングはUTF-16コードユニット単位の部分文字列比較なので、日本語の部分一致検索自体は問題なく動作します。「プロンプト管理」で検索すれば「Langfuseのプロンプト管理機能は〜」にヒットします。
ClickHouse側(Traces / Observations)の日本語対応#
packages/shared/src/server/queries/clickhouse-sql/search.tsを読むと、サーバーサイドの検索は以下のSQLで実現されています。
input ILIKE '%クエリ文字列%' OR output ILIKE '%クエリ文字列%'ClickHouseのILIKEはLIKEの大文字小文字非区分版で、内部的にはバイト列に対するパターンマッチとして動作します。ClickHouseのスキーマを確認すると、input/outputカラムはNullable(String) CODEC(ZSTD(3))で定義されており、tokenbf_v1やngrambf_v1などのフルテキストインデックスは設定されていません。
もし仮にtokenbf_v1(トークンベースのbloom filter)が使われていた場合、デフォルトのトークナイザは空白・句読点で分割するため、日本語のように分かち書きしない言語では検索精度に影響が出る可能性があります。しかし、現状のILIKE ‘%…%‘によるパターンマッチであれば、たとえ日本語文字列でも部分一致検索として機能します。
トレードオフとして、先頭ワイルドカード付きのILIKEはインデックスが効かず、該当カラムの全行スキャンが発生します。大量のtracesがあるプロジェクトでは(データが日本語でもそうでなくても)パフォーマンスへの影響があり得ることには注意が必要です。
PostgreSQL側(Prompt一覧)の日本語対応#
web/src/features/prompts/server/routers/promptRouter.tsを見ると、プロンプト本文検索は以下のPrisma SQLで行われています。
p.prompt::text ILIKE '%クエリ文字列%'promptカラムはJSON型で、::textでテキストにキャストした上でILIKEを適用しています。PostgreSQLのILIKEはロケール依存のケースフォールディングを行うため、日本語文字列に対しても部分一致検索が機能します。ClickHouseと同様、GINインデックスなどは設定されていないため全行スキャンとなりますが、Langfuseの使い方として「プロンプトを大量に登録する」ことはあまりmajorな使い方ではないと思われるため、この点が問題になる可能性はあまり高くないかもしれません。
まとめ:現行の制約(Limitation)一覧#
Langfuseの検索を日本語で使う際に把握しておきたい制約を一覧にまとめます。
検索の基本特性#
- 「文字列を探す検索」である:ステミング(語形変化の吸収)、同義語展開、関連度スコアリングといった、狭義の全文検索が提供する機能はない
- 形態素レベルの検索はできない:「走る」で「走った」「走り」はヒットしない
- ひらがな/カタカナの同一視はされない:「ぷろんぷと」で「プロンプト」はヒットしない
TextモードとChatモードの差異#
- 全角/半角の扱いが異なる:Textモード(CodeMirror組み込み検索)ではNFKD正規化により全角/半角が相互にヒットするが、Chatモード(PR #12578のcontroller)ではヒットしない
- Chatモードではカウンターとハイライトが食い違うケースがある:controllerのマッチカウンターと、CodeMirrorの
highlightSelectionMatchesで正規化処理が異なるため
サーバーサイド検索#
- インデックスなしの全行スキャン:ClickHouse/PostgreSQLともにILIKEパターンマッチでインデックスが効かないため、データ量が増えた場合のパフォーマンスは注視が必要
- API経由の検索はまだ非対応:GitHub Discussion #12373でPublic API経由の検索のリクエストが上がっており、近々対応される可能性はある
総括#
今回のPR #12578は 、Playgroundという「手元で試す」場面に対して、シンプルかつ確実に動く検索を提供しています。日本語ユーザーとしては、今のところ「普通に使えてありがたい」というのが正直な感想ですが、今回の記事中で指摘した不整合は気になるため、Langfuseコミュニティにfeedbackしておこうと思います(&feedbackが反映されたらまた記事として触れさせて頂くかもしれません!)。